Vorüberlegungen
Bevor mit der Übersetzung in Zwischencode begonnen werden kann, muss zunächst geklärt werden, wie dieser aussehen soll und wie Knoten des Syntaxbaumes als Zwischencode dargestellt werden sollen. Bei Letzterem ist vor Allem die Repräsentation von Variablen ein nicht trivialer Aspekt.
Elemente des Zwischencodes
Eine Zwischencodedarstellung sollte sich sowohl einfach aus Quellsprachen generieren lassen als auch einfach in Maschinensprachen zu übersetzen sein. Zwischencode ist eine abstrakte Maschinencodedarstellung, die nur die grundlegendsten Operationen enthält, mit denen sich aber sowohl Konstrukte spezieller Programmiersprachen als auch spezielle Maschinenanweisungen emulieren lassen. Damit ist eine Unabhängigkeit von Quell- und Zielsprache gegeben, was Voraussetzung für den modularen Aufbau eines Compilers mit auswechselbaren Front- und Backends ist.
Die gewählte Zwischensprache orientiert sich sehr stark an der des Buches Modern Compiler Implementation in Java. Im Folgenden seien ihre Elemente und deren Bedeutung vorgestellt.
Man unterteilt die Elemente der Zwischensprache grob in zwei Klassen, Ausdrücke (Exp) und Anweisungen (Stm). Ein Programm in Zwischencodedarstellung besteht dabei aus einer Folge von Anweisungen, welche Ausdrücke enthalten können. Ausdrücke können nicht ohne die umgebende Anweisung existieren. Es werden zunächst die Ausdrücke vorgestellt:
CONST(int value) | Ein konstanter Zahlenwert. |
TEMP(Temp temp) | Inhalt eines temporären Speicherplatzes. Ein temporärer Speicherplatz Temp entspricht einem Register in einer echten Maschine, die Anzahl der Temps ist aber unbegrenzt. |
BINOP(int binop, Exp left, Exp right) | Eine binäre Operation. Dabei ist binop der Operator, left und right sind Ausdrücke, die vor Anwendung der Operation ausgewertet werden. Der Binäroperator kann sein "addieren", "subtrahieren", "multiplizieren", "dividieren", "bitweises Und" (AND), "bitweises Oder" (OR), "bitweises exklusives Oder" (XOR), "logisches Linksschieben" oder "logisches Rechtsschieben". |
MEM(Exp exp) | Inhalt einer oder mehrerer Speicherzellen. Der Ausdruck exp wird vor dem Speicherzugriff ausgewertet und dient als Speicheradresse. Es werden n Bytes ab dieser Adresse gelesen, dabei ist n die Wortgröße der Zielmaschine. Die Wortgröße wird ist im angeschlossenen Backend definiert und aus diesem über eine definierte Schnittstelle ausgelesen. |
CALL(Exp func) | Ruft eine Unterprozedur auf und liefert das Ergebnis zurück. |
Die Zwischensprache enthält folgende Anweisungen:
MOVE(Exp dst, Exp src) | Eine Kopieroperation. Der Wert src wird in n Byte des Speichers geschrieben, wobei dst die Startadresse des zu beschreibenden Speichers ist und n die Wortgröße. |
EXP(Exp exp) | Berechnet den Wert des Ausdrucks exp und verwirft das Ergebnis. Dieses Konstrukt wird im Projekt ausschließlig dazu verwendet, einen Funktionsaufruf (CALL), der vom Typ Exp ist, als Anweisung (Stm) verwenden zu können. |
JUMP(Label label) | Ein Sprung zur Stelle im Code, die mit LABEL(label) markiert wurde. |
CJUMP(int relop, Exp left, Exp right, Label iftrue, Label iffalse) | Ein bedingter Sprung. Es werden zuerst die Ausdrücke left und right ausgewertet, anschließend wird auf sie der Relationsoperator relop angewendet. Wenn left und right in der Beziehung relop zueinander stehen, wird zum Label iftrue gesprungen, andernfalls zum Label iffalse. Relationsoperator kann sein "gleich", "ungleich", "größer", "kleiner", "größer gleich" oder "kleiner gleich". |
SEQ(Stm left, Stm right) | Eine Sequenz von Anweisungen. Die Anweisung left wird vor der Anweisung right ausgeführt. |
LABEL(Label label) | Markiert eine Stelle im Quellcode, die das Ziel von Sprüngen sein kann. |
INPUT(MEM address) | Eine Eingabeaufforderung, der eingegebene Wert wird an Speicheradresse address gespeichert.Ein- und Ausgabe sollten eigentlich in Form einer Laufzeitbibliothek implementiert oder als Assembleranweisungen in den Zwischencode eingebunden werden, denn ein INPUT Knoten ist sehr speziell auf eine Eingabe von Konsole ausgerichtet. Eingaben können aber beispielsweise auch über grafische Benutzerschnittstellen erfolgen. Aus Gründen der Einfachheit und des akademischen Charakters des Compilers wurde aber INPUT in den Zwischencode aufgenommen. |
OUTPUT(Expression exp) | Ausgabe des Wertes exp auf der Konsole. Es gelten analog die selben Anmerkungen wie beim INPUT. |
Alle Elemente des Zwischencodes sind als Knoten implementiert, es wird also der Syntaxbaum in einen Zwischencodebaum transformiert.
Variablenrepräsentation
Wichtig für einen späteren korrekten Programmablauf ist, dass Variablen des Quellprogramms korrekt auf Speicherzellen abgebildet werden. Dabei kann man nicht einfach den Namen der Variablen als Unterscheidungsmerkmal heranziehen, denn Variablen können durchaus den selben Namen haben, wenn sie in unterschiedlichen Gültigkeitsbereichen liegen. Beim rekursiven Aufruf einer Prozedur müssen jedesmal neue Adressen für die deklarierten Variablen vergeben werden, denn jeder Aufruf öffnet einen neuen Gültigkeitsbereich. Eine Möglichkeit, dies umzusetzen sei im Folgenden erläutert. Sie wurde dieser Powerpoint-Präsentation entnommen.
Folgende Grafik zeigt einen Ausschnitt des Hauptspeichers:
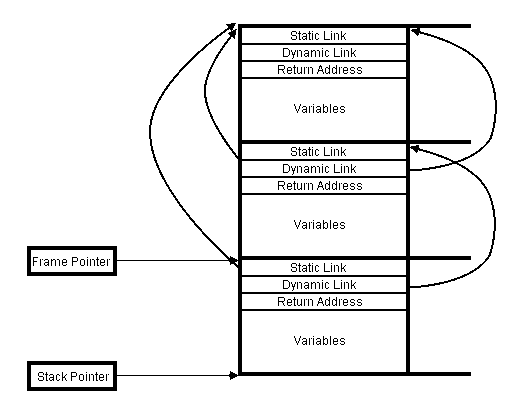
Abbildung 4.1: Aktivierungssegmente
Die dick eingerahmten Kästchen sind die sogenannten Aktivierungssegmente. Sie enthalten drei reservierte Felder und eine beliebige Anzahl von Variablen. Sie werden in einer Kellerstruktur abgelegt. Auf dem Bild sind drei Aktivierungssgemente zu sehen, der Keller wächst nach unten. Für die Programmausführung ist grundsätzlich das unterste Aktivierungssegment von Bedeutung. In ihm sind die Variablen enthalten, die lokal im gerade abzuarbeitenden Gültigkeitsbereich deklariert wurden. Der Frame-Pointer zeigt immer auf das unterste Segment, der Stack-Pointer zeigt immer auf das Ende des untersten Segmentes. Wird ein neuer Gültigkeitsbereich betreten, z.B. durch Prozeduraufruf, muss ein neues Segment in den Keller gelegt werden. Der Stack-Pointer ist dabei die Anfangsadresse dieses neuen Segmentes. Nach Einrichtung des Segmentes nimmt der Frame-Pointer den Wert des Stack-Pointers an und der Stack-Pointer rückt wieder ans Ende.
Statische Links
Wenn man auf Variablen zugreifen möchte, die in einem übergeordneten Gültigkeitsbereich definiert sind, so muss man auf das entsprechende Aktivierungssegment zugreifen. Dieses erreicht man, indem man dem statischen Link folgt. Es lässt sich feststellen, dass der statische Link zum nächstgelegenen Aktivierungssegment zeigen muss, welches eine Hierarchiestufe über aktuellen neuen Segment steht. Das klingt verwirrend, ist es auch. Darum sei hier ein Beispiel gegeben, welches sich an Abbildung 4.1 orientiert:
VAR i,j;
PROCEDURE p1;
VAR i, k;
BEGIN
i := 1;
j := 2;
k := 3;
CALL p1;
END;
BEGIN
CALL p1;
END.
|
Das oberste Segment gehört dem Hauptprogramm. Als Variablen werden i und j eingetragen, der Variablenbereich enthält also Platz für zwei Werte. Beim Aufruf der Prozedur p1 im Hauptprogramm wird das neue Segment aufgebaut. Es ist 5 Felder groß: die drei reservierten Felder und zwei Felder für die Variablen i und k. Der statische Link zeigt auf das erste Segment, weil dies das "umgebende" ist. Bei der Zuweisung von 2 an j wird dem statischen Link gefolgt und dann der Wert 2 an die Stelle für die zweite Variable geschrieben (weil j als zweite Variable definiert wurde). Nach der Zuweisung k := 3; wird aus p1 erneut p1 aufgerufen. Ein neues Aktivierungssegment mit neuen Variablen wird angelegt, denn Zuweisungen an i und k dürfen keinen Einfluss auf die Variablen der aufrufenden "Instanz" von p1 haben. Nun darf aber der statische Link nicht einfach auf das aufrufende Segment zeigen, denn dann gäbe es einen Link vom neuen p1 auf das alte p1, was ein Fehler wäre, wenn man diesem Link folgte, um auf das globale j zuzugreifen. Deshalb zeigt der statische Link des dritten Segments auf die gleiche Stelle wie der des zweiten Segments, in diesem Fall nach ganz oben.
Zur weiteren Veranschaulichung sei gezeigt, wie der Zugriff auf Variablen konkret im Zwischencode (und analog im Maschinencode) dargestellt wird:
MEM(+(TEMP(Temp fp), CONST(3)))
MEM(+(MEM(+(TEMP(Temp fp), CONST(0)), CONST(3))))
|
In der ersten Zeile erfolgt ein Zugriff auf die erste Variable des aktuellen Segments an der Stelle Framepointer + 3. (die 3 ist der Offset der ersten Variable, direkt nach den 3 Spezialfeldern). Falls die Wortbreite des Zielsystems mehr als 1 Byte ist (normalerweise 4 Byte, bei 64 Bit Rechnern 8 Byte), muss die 3 durch eine 12 (Offset 3 * 4 Byte) bzw. 24 (Offset 3 * 8 Byte) ersetzt werden. Man erkennt, dass der Zwischencode nicht komplett maschinenunabhängig sein kann. Die Information über die Wortbreite kann aber über eine definierte Schnittstelle aus dem angeschlossenen Backend geholt werden, so dass die Kopplung Zwischencode - Backend zumindest ziemlich lose ist.
In der zweiten Zeile wird zunächst der Inhalt des Frame-Pointers mit dem Offset des statischen Links (0) addiert, um dessen Adresse zu ermitteln. Da das ganze von MEM umgeben ist, bedeutet dies, dass der Wert, der an dieser Stelle des Hauptspeichers steht, gelesen wird. Der Wert des statischen Links ist die Adresse des "umgebenden" Segments. Zu dieser Adresse wird 3 addiert (bzw. 12 oder 24), um die Adresse der ersten Variablen dieses Segments zu berechnen. Mit MEM wird wie oben der Wert dieser Variablen gelesen. Diese MEM Zugriffe lassen sich beliebig schachteln, je nachdem, wie viele Stufen man sich nach oben hangeln muss.
Nun, da geklärt ist, wohin die statischen Links zeigen müssen, und wie sie die Variablenrepäsentation beeinflussen, soll erläutert werden, wie sie zur Laufzeit eigentlich aufgebaut werden. Den statischen Link korrekt zu setzen, wenn ein neues Aktivierungssegment eingefügt wird, bedarf nämlich etwas Aufwands.
Wie bereits erwähnt, muss der statische Link zum nächstgelegenen Aktivierungssegment zeigen, welches eine Hierarchiestufe über dem neuen Segment steht. Dazu ist es nötig, die Hierarchiestufen eines jeden Güligkeitsbereichs zur Laufzeit in Erfahrung zu bringen, sowie herauszufinden, welche Hierarchiestufe zum aktuellen Aktivierungssegment gehört.
Aus diesem Grund wird ein sogenanntes level Attribut eingeführt.
Beim Prozeduraufruf wird festgestellt, wie groß die Differenz der Level des neuen und des alten Aktivierungssegments ist. Ist sie -1, so wird der statische Link des neuen Aktivierungssegmentes auf die Anfangsadresse des aufrufenden Segmentes gesetzt, weil eine Prozedur eine direkte Unterprozedur aufgerufen hat. Ist die Differenz 0 oder größer, so wurde eine Prozedur der selben Hierarchiestufe oder einer höheren aufgerufen. Man folgt deshalb differenz + 1 statischen Links, auf das so erhaltene Segment muss der neue statische Link zeigen. Am folgendem Beispiel sei das noch einmal verdeutlicht. Bei Ausführung dieses Programmes:
PROCEDURE p1;
PROCEDURE p11;
BEGIN
CALL p12;
END;
PROCEDURE p12;
PROCEDURE p121;
BEGIN
CALL p2;
END;
BEGIN
CALL p121;
END;
BEGIN
CALL p11;
END;
PROCEDURE p2;
BEGIN
END;
BEGIN
CALL p1;
END.
|
wird folgender Datenstack samt statischer Links aufgebaut:
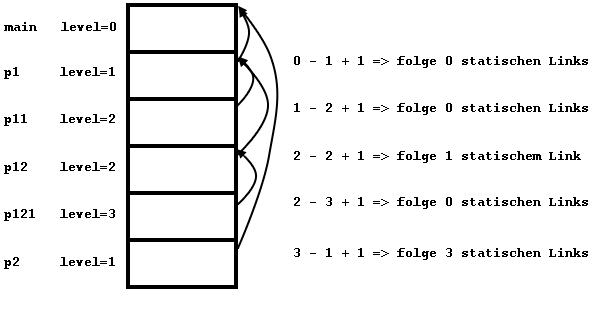
Abbildung 4.2: Setzen der statischen Links
Dynamische Links und Rücksprungadressen
Dynamische Links zeigen immer auf das vorige Segment. Das ist notwendig, damit beim Verlassen eines Segments der Frame-Pointer zum Anfang des vorigen Segments zurückgeschoben werden kann. Die Rücksprungadresse sagt dem Programmzähler, an welcher Stelle im Codesegment die Programmausführung fortgesetzt werden soll, wenn das Segment verlassen wird. Im Zwischencode spielt dieses Feld keine Rolle.
Implementierung
Anpassen des Syntaxbaumes
Nachdem der Syntaxbaum aufgebaut und Symboltabelle gefüllt ist, könnte die eigentliche Übersetzung in Zwischencode beginnen. Das ließe sich erreichen, indem für jeden Knoten gefragt wird, was er darstellt (Binäroperation, Prozeduraufruf, While-Schleife, ...) und man dann die entsprechende Transformation durchführt. Dieses Verfahren ist allerdings wenig objektorientiert. Viel schöner wäre es, wenn jeder Knoten eine Methode hätte, die ihn transformiert. Die Baumknoten erben von einem Oberknoten, so dass immer nur die Transformiermethode der Kinder eines Knotens aufgerufen werden muss, um den gesamten Baum umzuwandeln, ohne dass es notwendig ist, zu wissen, welche Kindknoten tatsächlich vorliegen.
Dazu ist es aber nötig, bei der Generierung des Syntaxbaumes einzugreifen, denn grundsätzlich sind alle Knoten des Syntaxbaumes vom Typ antlr.CommonAST. Glücklicherweise kann man in der Parserdefinition die Klassen der zu erzeugenden Knoten festlegen. Diese Klassen müssen Unterklassen von CommonAST sein. Die endgültige Parserdefinition sieht wie folgt aus:
header {
package frontend.parser;
import frontend.symbol.*;
import java.util.LinkedList;
}
class PL0Parser extends Parser;
options {
defaultErrorHandler=false;
buildAST = true;
}
tokens {
EXPR;
BLOCK;
CONSTASSIGN;
VAR;
CONSTD;
PROC;
PROGRAM<AST=frontend.parsetree.ProcedureNode>;
ASSIGNOP<AST=frontend.parsetree.AssignNode>;
NUMBER<AST=frontend.parsetree.NumberNode>;
IDENT<AST=frontend.parsetree.IdentNode>;
PLUS<AST=frontend.parsetree.BinopNode>;
MINUS<AST=frontend.parsetree.BinopNode>;
TIMES<AST=frontend.parsetree.BinopNode>;
OVER<AST=frontend.parsetree.BinopNode>;
EQUALS<AST=frontend.parsetree.BinrelNode>;
DIAMOND<AST=frontend.parsetree.BinrelNode>;
LT<AST=frontend.parsetree.BinrelNode>;
LEQ<AST=frontend.parsetree.BinrelNode>;
GT<AST=frontend.parsetree.BinrelNode>;
GEQ<AST=frontend.parsetree.BinrelNode>;
QUESTION<AST=frontend.parsetree.InputNode>;
EXCLAM<AST=frontend.parsetree.OutputNode>;
}
{
SymbolTable symbolTable = SymbolTable.getSymbolTable();
private boolean pendingMinus = false;
private LinkedList exceptions = new LinkedList();
...
}
program: block DOT! {#program = #([PROGRAM, "PROGRAM"], program); resolveUnknown();};
block: (constdecl!)? (vardecl!)? (procdecl)* statement;
constdecl: "CONST" constassign (COMMA constassign)* SEMICOLON;
constassign: i:IDENT EQUALS n:NUMBER { checkRange(n); defineConst(i, n); };
vardecl: "VAR" i1:IDENT {defineVar(i1);} (COMMA i2:IDENT {defineVar(i2);})* SEMICOLON;
procdecl: "PROCEDURE"^<AST=frontend.parsetree.ProcedureNode>
i:IDENT {defineProcedure(i);} SEMICOLON! block SEMICOLON! {popScope();};
statement: (i:IDENT {checkForVariable(i);} ASSIGNOP^ expression
| "CALL"^<AST=frontend.parsetree.CallNode> i2:IDENT {checkForProcedure(i2);}
| QUESTION^ i3:IDENT {checkForVariable(i3);}
| EXCLAM^ i4:IDENT {checkForValue(i4);}
| "BEGIN"^<AST=frontend.parsetree.BeginNode>
statement (SEMICOLON! statement)* "END"!
| "IF"^<AST=frontend.parsetree.IfNode> condition "THEN"! statement
| "WHILE"^<AST=frontend.parsetree.WhileNode> condition "DO"! statement)?;
condition: "ODD"^<AST=frontend.parsetree.OddNode> expression
| expression (EQUALS^ | DIAMOND^ | LT^ | LEQ^ | GT^ | GEQ^) expression;
expression: (PLUS^<AST=frontend.parsetree.PlusNode>
| MINUS^<AST=frontend.parsetree.MinusNode> {pendingMinus = true;})?
term {pendingMinus = false;}((PLUS^ | MINUS^) term)*;
term: factor ((TIMES^ | OVER^) factor)*;
factor: i:IDENT {checkForValue(i);}
| n:NUMBER {checkRange(n);}
| LPAREN! expression RPAREN!;
|
Die Tokens-Sektion wurde erweitert, damit die Festlegung der Knotenart nicht innerhalb der eigentlichen Grammatik geschehen muss. Alles was sich aus bereits genannten Gründen (siehe Definition des Scanners) nicht als Token verwenden ließ (Schlüsselworte), wurde allerdings notgedrungen in der Grammatik ausgezeichnet. Man beachte, dass auch in der Regel expression die Knoten PLUS und MINUS ausgezeichnet wurden. Der Grund ist, dass PLUS und MINUS hier Vorzeichen sind und keine Binäroperationen.
Die komplette Parser- und Scannerdefinition zum Übersetzen steht zum Download bereit. Die Syntax für das Übersetzen lautet unter Windows
java -cp antlr.jar; antlr.Tool PL0_Grammar.g
|
Das Resultat sind ein Scanner und ein Parser in Java. Sie liegen im Quellcode vor.
Aufbau der neuen Syntaxbaumknoten
Alle oben verwendeten Knoten sind Unterklassen von PL0Node, welche wiederum von CommonAST aus dem ANTLR-Paket abgeleitet ist. PL0Node definiert die Methoden convertStatement(), convertExpression() und convertConditional(Label t, Label f). Diese Methoden werden in den Unterklassen nach Bedarf implementiert. Im Folgenden seien einige wichtige Implementierungen näher erläutert, die Implementation der restlichen Knoten ist ähnlich.
AssignNode
Variablenzuweisungen resultieren in einem Zusweisungsknoten, dem sogenannten AssignNode. Eine Zuweisung ist eine Anweisung im Quelltext, also ein Statement. Deshalb implementiert AssignNode die Methode convertStatement:
public Statement convertStatement() {
PL0Node dest = (PL0Node)getFirstChild();
PL0Node src = (PL0Node)dest.getNextSibling();
return new MOVE(dest.convertExpression(), src.convertExpression());
};
|
Ein Zuweisungsknoten hat immer zwei Kinder: das Zuweisungsziel und den Zuweisungswert. Diese beiden Kinder werden mit getFirstChild() und getNextSibling() (definiert in BaseAST, der Oberklasse von CommonAST) geholt und abgespeichert. Dabei sind sowohl dest als auch src Werte und damit vom Typ Expression (dest ist eine Adresse, src ist der zuzuweisende Wert). Für beide wird daher die Methode convertExpression() aufgerufen, die Ergebnisse stehen innerhalb eines MOVE Knotens im resultierenden Zwischencodebaum: der Wert src wird im Speicher auf die Adresse dest geschoben. Wie man erkennt, wird der Zwischencodebaum rekursiv absteigend erzeugt.
IfNode
Eine bedingte Anweisung wird im Syntaxbaum als sogenannter IfNode dargestellt. Dieser hat als Kinder einen Bedingungsknoten (BinrelNode bei binären Vergleichen oder OddNode bei Prüfung auf Ungeradheit einer Zahl) und einen Anweisungsknoten. Bei der Übersetzung wird zuerst geprüft, ob die Bedingung erfüllt ist. Falls ja, wird zur Anweisung gesprungen und diese ausgeführt, andernfalls wird an eine Stelle nach dieser Anweisung gesprungen. Eine bedingte Anweisung der Form
IF a < b THEN <doSomething>;
|
wird beispielsweise übersetzt zu
CJUMP(<, a, b, true, false)
LABEL(true)
<doSomething>
JUMP(false);
LABEL(false);
|
Man beachte, dass dies eine vereinfachte Zwischencodedarstellung ist. In echtem Zwischencode wären beispielsweise die Variablen a und b bereits in Anweisungen zur Adressberechnung umgewandelt. Der unbedingte Sprung zum Label false kann theoretisch wegfallen, dies wird aber der Optimierungsstufe überlassen. Wenn der Sprung hier noch erhalten bleibt, lässt sich bei der Optimierung eventuell durch Neuordnung von Codeblöcken besserer Code generieren.
Eine kleine Schwierigkeit ergibt sich, weil bei der Umwandlung des Bedingungsknotens in Zwischencode die Labels, die in der CJUMP-Anweisung stehen, die gleichen sein müssen, die im IfNode als Sprungziele vereinbart sind. Schwierigkeit deshalb, weil jedes erzeugte Label einen neuen Namen bekommt, so dass im IfNode und im Bedingungsknoten nicht die gleichen Labels erzeugt werden können. Die Lösung ist, die im IfNode erzeugten Labels der convertConditional() Methode des Bedingungsknotens als Parameter zu übergeben. Der endgültige Code sieht so aus:
public Statement convertStatement() {
Label t = new Label(); //erzeugt Label mit eindeutiger ID
Label f = new Label(); //erzeugt ein weiteres Label mit eindeutiger ID
PL0Node condNode = (PL0Node)getFirstChild();
PL0Node execNode = (PL0Node)condNode.getNextSibling();
Statement condStm = condNode.convertConditional(t, f); //t und f werden für die
//Konvertierung des Bedingungs-
//knotens übergeben
Statement execStm = execNode.convertStatement();
return new SEQ(condStm, new SEQ(new LABEL(t),
new SEQ(execStm, new SEQ(new JUMP(f),
new LABEL(f)))));
};
|
ProcedureNode
Der Prozedurknoten ist etwas Besonderes. Er hat keine der createXXX() Methoden von PL0Node implementiert, da niemals andere Knoten die Umwandlung eines ProcedureNode anstoßen können. Stattdessen gibt es die Methoden createIntermediateCode() und createAll(). Dies sieht folgendermaßen aus:
public CodeContainer createIntermediateCode() {
cc = new CodeContainer();
PL0Node node = (PL0Node)getFirstChild();
createAll(node, 0);
return cc;
}
private void createAll(PL0Node node, int number) {
if (node instanceof IdentNode) {
node = (PL0Node)node.getNextSibling();
}
while (node instanceof ProcedureNode) {
String procname = node.getFirstChild().getText();
ScopeDef sd = (ScopeDef)table.lookup(procname);
table.pushScope(sd);
createAll((PL0Node)node.getFirstChild(), sd.getScopeNumber());
table.popScope();
node = (PL0Node)node.getNextSibling();
}
if (node != null) {
cc.addCode(node.convertStatement(), number);
}
}
|
Man beachte, dass das Hauptprogramm auch vom Typ ProcedureNode ist, da es fast identisch zu einer Prozedur aufgebaut ist. Der einzige Unterschied liegt darin, dass das Hauptprogramm keinen Prozedurnamen hat.
Die Umwandlung des Syntaxbaumes in den Zwischencodebaum beginnt mit dem Aufruf von createIntermediateCode(). Es wird ein CodeContainer erzeugt. Dieser CodeContainer ist im Wesentlichen eine Hashmap. In dieser Hashmap werden als Werte die erzeugten Zwischencodebäume gespeichert; jeder Gültigkeitsbereich (also jede Prozedur und das Hauptprogramm) werden zu einem Eintrag im CodeContainer. Der zugehörige Schlüssel wird die sogenannte scopeNumber (siehe Numerieren der Prozeduren).
In der Methode createAll(PL0Node node, int number) werden alle Unterprozeduren der aktuellen Prozedur bearbeitet. Nachdem dies geschehen ist, wird der Anweisungsblock der Prozedur in Zwischencode transformiert und im CodeContainer unter der scopeNumber gespeichert.
Detaillierte Erklärung:
Der Knoten node, der createAll() übergeben wird, ist immer ein ProcedureNode. Ein ProcedureNode hat als erstes Kind den Prozedurnamen, danach beliebig viele weitere ProcedureNodes und einen Anweisungsknoten (meist ein BeginNode). Das Hauptprogramm hat als erstes Kind keinen Prozedurnamen. In der If-Anweisung wird getestet, ob das erste Kind des zu bearbeitenden Knotens dieser Prozedurname ist. Falls ja, wird er übersprungen, er ist unwichtig. In einem Durchlauf der folgenden While-Schleife wird jedesmal eine weitere ProcedureDef bearbeitet. Zuerst wird der Name der Prozedurdefinition ermittelt und mit dessen Hilfe die korrekte ScopeDef aus der Symboltabelle geholt. Diese ScopeDef wird auf den ScopeStack gelegt. Als nächstes wird die createAll() Methode für diese in der aktuellen Prozedur enthaltene Prozedur ausgeführt. Nachdem alle Unterprozeduren bearbeitet wurden, wird die ScopeDef wieder vom Stack genommen und der nächste Knoten wird in node gespeichert.
Wenn alle ProcedureNodes abgearbeitet sind und als nächstes ein Anweisungsknoten im Baum steht, wird dieser in Zwischencode umgewandelt und unter seiner scopeNumber im CodeContainer gespeichert. Auf diese Art werden alle Prozeduren nacheinander transformiert und abgespeichert.
Die Benutzung des scopeStack verdient vielleicht besondere Aufmerksamkeit. Er wird benutzt, damit beim Auftauchen eines Bezeichners im Syntaxbaum festgestellt werden kann, auf welchen Gültigkeitsbereich sich dieser bezieht. Zur Erinnerung: Ein Bezeichner kann auch umgebende Gültigkeitsbereiche referenzieren. Mit dem Stack wird sichergestellt, dass das Auflösen des Bezeichnernamens in der korrekten Variable, Konstante oder Prozedur resultiert.
IdentNode
Die eben angesprochene Nutzung des scopeStack soll nun am Beispiel der IdentNode konkretisiert werden. In Abschnitt Variablenrepräsentation wurde bereits ausführlich auf die Variablenrepräsentation im Zwischencode eingegangen. Daraus ergibt sich folgender Transformationscode:
public Expression convertExpression() {
int[] pos = SymbolTable.getSymbolTable().lookupPos(getText());
Expression ident = new TEMP(frame.fp());
for (int i = 0; i < pos[0]; i++) {
ident = new MEM(new BINOP(BINOP.PLUS, ident, new CONST(frame.STATIC_LINK * frame.wordSize())));
}
ident = new MEM(new BINOP(BINOP.PLUS, ident, new CONST((pos[1] + frame.getMinOffset()) * frame.wordSize())));
return ident;
}
|
Die Methode lookupPos() der Symboltabelle liefert ein zweispaltiges Array zurück. An Stelle 0 wird mit Hilfe des scopeStack gespeichert, wieviele Gültigkeitsbereiche traversiert werden mussten, um den Bezeichner zu finden. Das entspricht der Anzahl der statischen Links, die zu verfolgen sind. In der For-Schleife wird dementsprechend für jeden Gültigkeitsbereich rekursiv eine Static-Link-Verfolgung aufgebaut. Die Stelle 1 des Arrays pos liefert die Position innerhalb des Gültigkeitsbereichs, an der der Bezeichner definiert wurde. Daraus wird der Offset berechnet, über den auf die Variable innerhalb des Aktivierungssegments zugegriffen werden kann. Zur Erinnerung: vor den Konstanten und Variablen gibt es reservierte Felder, den statischen und den dynamischen Link sowie die Rücksprungadresse.
CallNode
Zum Abschluss sei der Prozeduraufrufknoten vorgestellt:
public Statement convertStatement() {
PL0Node parameter = (PL0Node)getFirstChild();
ScopeDef sd = (ScopeDef)SymbolTable.getSymbolTable().lookup(parameter.getText());
int number = sd.getScopeNumber();
return new EXP(new CALL(new CONST(number)));
};
|
Es wird in der Symboltabelle nachgesehen, auf welche Prozedur sich der Prozedurname bezieht (Es können mehrere Prozeduren in verschiedenen Gültigkeitsbereichen den gleichen Namen haben). Wurde diese Prozedur gefunden, wird der Zwischencodebaum aufgebaut. Der Parameter des CALL ist die scopeNumber der referenzierten Prozedur. Der CALL Knoten ist aber ein Ausdruck und keine Anweisung (siehe Elemente des Zwischencodes). Er wird deshalb in einen EXP Knoten eingebettet.
 Die Symboltabelle Die Symboltabelle | Linearisierung des Zwischencodes  |