Aufgabe der Symboltabelle
Als nächstes wurde die Symboltabelle implementiert. Sie hat die Aufgabe, Konstanten-, Variablen- und Prozedurdefinitionen aufzunehmen. Grundsätzlich müssen auch die vereinbarten Datentypen und die Rückgabetypen von Funktionen abgespeichert werden. Da es in PL/0 aber nur Integer gibt und Funktionen nichts zurückliefern, konnte darauf verzichtet werden. Bei der statischen semantischen Analyse und der Codegenerierung wird auf die in der Symboltabelle gespeicherten Informationen Bezug genommen.
Die Struktur der Symboltabelle orientiert sich stark an der des Cross Reference Tools, welches von den ANTLR-Entwicklern für eine Artikelserie veröffentlicht wurde.
Aufbau der Symboltabelle
Gültigkeitsbereiche
Die Art und Weise, in der die beim Parsen gewonnenen Informationen abgespeichert werden sollen, bestimmt wesentlich den Aufbau der Symboltabelle. Wenn Variablen, Konstanten und Prozeduren deklariert werden, so haben sie einen bestimmten Gültigkeitsbereich, innerhalb dessen sie referenziert werden können. Außerhalb des Gültigkeitsbereichs kann nicht auf sie zugegriffen werden. Gütigkeitsbereiche können geschachtelt werden. Sie sind dadurch gekennzeichnet, dass in ihnen Bezeichner deklariert werden können. In PL/0 sind daher nur das Hauptprogramm und Prozeduren Gültigkeitsbereiche.
So darf beispielsweise eine Variable i, die lokal innerhalb einer Prozedur deklariert wurde, nicht vom Hauptprogramm geschrieben oder gelesen werden. Andererseits darf von innerhalb einer Prozedur auf eine Variable, Konstante oder Prozedur zugegriffen werden, die in einer umschließenden Prozedur definiert wurde. Lokale Bezeichner dürfen den selben Namen haben, wie Bezeichner eines umgebenden Gültigkeitsbereichs. Wird ein solch mehrfach deklarierter Bezeichner vom Programm verwendet, so wird der des am nächsten umschließenden Gültigkeitsbereichs benutzt.
Folgender Code soll das noch einmal verdeutlichen:
VAR i,j;
PROCEDURE p1;
VAR i, k;
BEGIN
i := 1;
j := 2;
k := 3;
!i;
!j;
!k;
END;
BEGIN
i := 50;
j := 60;
!i;
!j;
CALL p1;
!i;
!j;
END.
|
Die Ausgabe ist:
50
60
1
2
3
50
2
Die beiden Zuweisungen des Hauptprogramms belegen die globalen Variablen i und j, die in der ersten Zeile definiert wurden. In der Unterprozedur werden die Variablen i und k der Unterprozedur belegt. Der Variablen j wird auch ein Wert zugewiesen, aber sie ist nicht innerhalb von p1 definiert. Deshalb wird j des nächsthöheren Gültigkeitsbereichs verwendet, dem Hauptprogramm. An den letzten beiden Ausgaben sieht man, dass die Zuweisung an i innerhalb der Unterprozedur keinen Einfluss auf i des Hauptprogramms hatte, j aber global geändert wurde. Prozeduren und Konstanten unterliegen den selben Regeln.
Struktur der Symboltabelle
In die Symboltabelle werden Definitionen von Bezeichnern (Variablen, Konstanten, Prozeduren) eingetragen. Diese Definitionen werden durch die abstrakte Klasse Definition repräsentiert. Sie kapselt die Position der Definition im Quelltext, ihren Gültigkeitsbereich und ihren Namen. Die Klassen VariableDef, ConstantDef und ScopeDef sind Unterklassen von Definition, die den exakten Typ der Definition darstellen. ScopeDef ist dabei etwas Besonderes, da es sowohl in einem Gültigkeitsbereich vorkommen kann (wie jede andere Definition), als auch selbst einen Gültigkeitsbereich darstellt, der wiederum andere Definitionen aufnehmen kann. Auf diese Art lassen sich beliebig tief geschachtelte Gültigkeitsbereiche modellieren. Die einzigen Gültigkeitsbereiche in PL/0 sind Prozeduren, ProcedureDef ist deshalb die einzige Unterklasse von ScopeDef.
Die Klasse SymbolTable, das Herz der Symboltabelle, enthält eine ScopeDef namens baseScope, welche das Hauptprogramm repräsentiert. Es gibt außerdem einen ScopeStack, einen Stack voller Gültigkeitsbereiche. Dabei repräsentiert die oben liegende ScopeDef den aktuellen Gültigkeitsbereich während des Parsingvorgangs.
Folgendes Diagramm verdeutlicht die eben beschriebenen Beziehungen grafisch. Die Klasse UnknownDef beschreibt Definitionen, die zum Zeitpunkt ihres Auftretens nocht nicht definiert sind, aber eventuell noch definiert werden. (siehe Statische semantische Analyse).
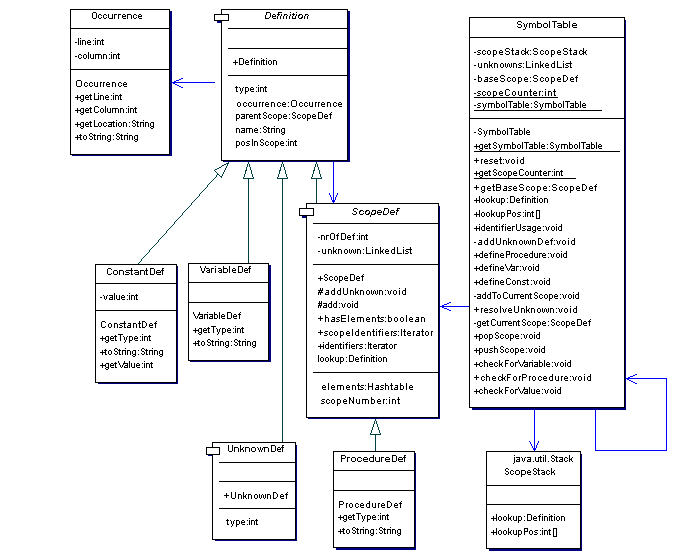
Abbildung 3.1: UML-Diagramm der Symboltabelle
Verwenden der Symboltabelle
Füllen der Symboltabelle
Beim Parsen werden alle gefundenen Definitionen der aktuellen ScopeDef, die oben auf dem ScopeStack liegt, hinzugefügt, außerdem wird in allen Definitions vermerkt, dass sie zu diesem Gültigkeitsbereich gehören. Wird ein neuer Gültigkeitsbereich (Prozedurdefinition) gefunden, so wird dieser auf den Stack gelegt, beim Verlassen des Bereichs wird er vom Stack entfernt.
Statische semantische Analyse
Damit der Syntaxbaum mit Hilfe der Symboltabelle zu einem korrekten Programm weiterverarbeitet werden kann, müssen einige Bedingungen erfüllt sein, die sich nicht allein mit der Syntaxanalyse überprüfen lassen. Dazu zählen bei PL/0:
- Variablen, Konstanten und Prozeduren müssen definiert sein.
- Werte dürfen nur Variablen zugewiesen werden.
- Nur Prozeduren dürfen mit
CALLaufgerufen werden.
In richtigen Programmiersprachen müsste man beispielsweise noch untersuchen, ob bei Zuweisungen die Typveräglichkeit gegeben ist.
Die statische semantische Analyse findet bereits während des Parsens statt. Wird das Auftreten eines Bezeichners festgestellt, so wird als semantische Aktion eine Methode ausgeführt, welche festzustellen hat, ob der Typ der gefunden Definition dem der tatsächlich erwarteten entspricht. Das geschieht, indem in der Symboltabelle nachgesehen wird (lookup()), ob die Definition gespeichert ist. Dabei wird zuerst der aktuelle Gültigkeitsbereich überprüft. Dieser liegt oben auf dem ScopeStack. Ist der Bezeichner dort nicht definiert, so wurde eventuell einer referenziert, der aus einem umgebenden Gültigkeitsbereich stammt. Deshalb wird im nächsten umgebenden Gültigkeitsbereich nachgesehen (der umgebende Gültigkeitsbereich ist als Attribut in jeder Definition (und damit wiederum in jeder ScopeDef) gespeichert). Das geschieht rekursiv so lange, bis die gesuchte Definition gefunden wurde oder bis festgestellt wurde, dass der gesuchte Bezeichner nirgendwo definiert ist.
- Wurde der Bezeichner in der Symboltabelle gefunden, wird festgestellt, ob er Variable, Konstante oder Prozedur beschreibt. Stimmt der gefundene Typ nicht mit dem erwarteten überein, wird eine entsprechende Exception geworfen.
- Wurde eine Variable oder Konstante erwartet, die aber nicht definiert ist, so wird eine Exception geworfen.
- Wurde eine Prozedur erwartet, die aber nicht definiert ist, so ist es möglich, dass sie noch definiert wird. Es wird eine "unbekannte Definition" (
UnknownDef) erzeugt, die in eine Liste unbekannter Definitionen aufgenommen wird. Nachdem der gesamte Quelltext geparst wurde, wird für alle Elemente dieser Liste getestet, ob die fehlende Prozedurdefinition inzwischen in einem für diesen Bezeichner sichtbaren Gültigkeitsbereich exisitiert. Falls nicht, wird eine entsprechende Exception geworfen.
Verbinden von Parser und Symboltabelle
Überprüfen der Bezeichnertypen
Für alle oben beschriebenen Überprüfungen muss ein während der Syntaxanalyse gefundener Bezeichner an die korrekte Testprozedur der Symboltabelle übergeben werden. Dazu kommen semantische Aktionen zum Einsatz.
header { package frontend.parser; import frontend.symbol.*; import java.util.LinkedList; } class PL0Parser extends Parser; options { defaultErrorHandler=false; buildAST = true; } tokens { PROGRAM; } { SymbolTable symbolTable = SymbolTable.getSymbolTable(); private LinkedList exceptions = new LinkedList(); public void popScope() { symbolTable.popScope(); } public LinkedList getExceptions() { return exceptions; } public void defineConst(Token constant, Token value) { Symbol s = new Symbol(constant, Symbol.SYMBOL_CONST); try { symbolTable.defineConst(s, Integer.parseInt(value.getText())); } catch(DoubleDeclarationException e) { exceptions.add(e.getMessage()); } } ... public void checkForDeclaration(Token t) { Symbol s = new Symbol(t); symbolTable.identifierUsage(s); } public void checkForVariable(Token t) { Symbol s = new Symbol(t); try { symbolTable.checkForVariable(s); } catch (NoVariableException nve) { exceptions.add(nve.getMessage()); } catch (NoDeclarationException nde) { exceptions.add(nde.getMessage()); } } ... public void resolveUnknown() { try { symbolTable.resolveUnknown(); } catch (NoDeclarationException e) { exceptions.add(e.getMessage()); } } } program: block DOT! {#program = #([PROGRAM, "PROGRAM"], program); resolveUnknown();}; block: (constdecl!)? (vardecl!)? (procdecl)* statement; constdecl: "CONST" constassign (COMMA constassign)* SEMICOLON; constassign: i:IDENT EQUALS n:NUMBER { defineConst(i, n); }; vardecl: "VAR" i1:IDENT {defineVar(i1);} (COMMA i2:IDENT {defineVar(i2);})* SEMICOLON; procdecl: "PROCEDURE"^ i:IDENT {defineProcedure(i);} SEMICOLON! block SEMICOLON! {popScope();}; statement: (i:IDENT {checkForVariable(i);} ASSIGNOP^ expression | "CALL"^ i2:IDENT {checkForProcedure(i2);} | QUESTION^ i3:IDENT {checkForVariable(i3);} | EXCLAM^ i4:IDENT {checkForValue(i4);} | "BEGIN"^ statement (SEMICOLON! statement)* "END"! | "IF"^ condition "THEN"! statement | "WHILE"^ condition "DO"! statement)?; condition: "ODD"^ expression | expression (EQUALS^ | DIAMOND^ | LT^ | LEQ^ | GT^ | GEQ^) expression; expression: (PLUS^ | MINUS^)? term ((PLUS^ | MINUS^) term)*; term: factor ((TIMES^ | OVER^) factor)*; factor: i:IDENT {checkForValue(i);} | NUMBER | LPAREN! expression RPAREN!; |
Zur Erläuterung:
Im Abschnitt header werden das Package definiert und Klassen aus anderen Packages importiert. Im Zuge der zunehmenden Komplexität des Compilers wurde eine Paketstruktur entworfen, in die sich der Parser einügen muss.
Die Anweisung defaultErrorHandler=false; bewirkt, dass die Standardfehlerbehandlung von ANTLR abgeschaltet wird und durch eine eigene ersetzt werden kann.
Es folgt ein Codeblock, der 1:1 in den generierten Parser übernommen wird. Es wird eine Referenz zur Symboltabelle angelegt, sowie eine Liste, in der eventuelle Fehler gespeichtert werden, die beim Parsen gefunden werden (beispielsweise Vorkommen nichtdefinierter Bezeichner). Der Rest sind Adaptermethoden, welche die Morpheme (Token), die der Parser verwendet, in Symbole umwandeln und damit Einfügeoperationen in die Symboltabelle und Tests durchführen. Token und Symbole unterscheiden sich nicht wesentlich. Die Symboltabelle arbeitet aber mit Symbolen statt direkt mit Token, damit sie nur lose an den von ANTLR erzeugten Parser gebunden ist.
Wenn während des Parsens eine Regel angewendet wird, werden alle semantischen Aktionen dieser Regel ausgeführt. Um auf ein bestimmtes Morphem, das in der Regel auftritt, in der zugehörigen semantischen Aktion Bezug zu nehmen, kann man es mit einer speziellen Syntax auszeichnen. So bedeutet beispielsweise die Zeile
constassign: i:IDENT EQUALS n:NUMBER { defineConst(i, n); };
|
dass bei der Anwendung der constassign-Regel das Morphem, welches als IDENT erkannt wurde, mit i referenziert werden kann, analog wird die NUMBER mit n angesprochen. In der semantischen Aktion können nun die Variablen i und n verwendet werden. Im Beispiel werden sie an die Methode defineConst() übergeben. Diese Methode ist im oben erwähnten Codeblock definiert. Sie wandelt i in ein Symbol um, n in eine Zahl, und trägt sie in die Symboltabelle ein. Falls das Symbol bereits definiert ist, wird im Catch-Block die Fehlermeldung der resultierenden Exception in die Fehlerliste aufgenommen.
Die meisten verwendeten Methoden haben einen selbsterklärenden Namen, so überprüft checkForVariable() beispielsweise, ob der gefunden Bezeichner bereits als Variable deklariert wurde. Einige Methoden verdienen aber eine Erwähnung. Mit checkForValue() wird getestet, ob der Bezeichner entweder Variable oder Konstante ist. Die Methode defineProcedure() trägt eine neue ProcedureDef in die aktuellen Gültigkeitsbereich der Symboltabelle ein und legt diese ProcedureDef als neuen Gültigkeitsbereich auf den ScopeStack. Nachdem die Prozedur verlassen wird, wird die ProcedureDef mit popScope() wieder vom Stack entfernt. Die Methode resolveUnknown() sorgt dafür, dass nach dem Parsen des gesamten Programmes überprüft wird, ob unbekannte Bezeichner mittlerweile definiert wurden. (siehe Statische semantische Analyse).
Bereichsüberprüfung bei Zahlen
Weiterhin sollte getestet werden, ob fest im Quelltext angegebene Zahlen nicht zu groß oder zu klein sind. Es wurde festgelegt, dass Zahlen 32 Bit breit und vorzeichenbehaftet sein sollen. Daraus ergibt sich ein Wertebereich von -2147483648 bis 2147483647.
Jede gefundene Zahl (Morphem NUMBER) wird auf Einhaltung dieses Wertebereichs untersucht. Da Integer in Java den exakt selben Wertebereich haben, wird zum Testen die Methode Integer.parseInt() ausgefürt. Ist die Zahl zu groß oder zu klein, erfährt man dies anhand der geworfenen NumberFormatException.
Da das Minuszeichen ein eigenes Morphem ist und für den Parser nicht mit zur folgenden Zahl gehört, wurde das Flag pendingMinus eingeführt. Immer wenn ein Minus vor einer Zahl auftritt, wird es true, damit die Testmethode weiß, ob die zu testende Zahl positiv oder negativ sein soll.
Am Ende ergab sich folgende Parserdefinition:
header {
package frontend.parser;
import frontend.symbol.*;
import java.util.LinkedList;
}
class PL0Parser extends Parser;
options {
defaultErrorHandler=false;
buildAST = true;
}
tokens {
PROGRAM;
}
{
SymbolTable symbolTable = SymbolTable.getSymbolTable();
private boolean pendingMinus = false;
private LinkedList exceptions = new LinkedList();
public void popScope() {
symbolTable.popScope();
}
...
public void checkRange(Token t) throws NumberOutOfRangeException {
String s = t.getText();
if (pendingMinus) {
s = '-' + s;
}
try {
Integer.parseInt(s);
}
catch (NumberFormatException e) {
exceptions.add(new NumberOutOfRangeException(s, t.getLine(), t.getColumn()).getMessage());
}
pendingMinus = false;
}
}
program: block DOT! {#program = #([PROGRAM, "PROGRAM"], program); resolveUnknown();};
block: (constdecl!)? (vardecl!)? (procdecl)* statement;
constdecl: "CONST" constassign (COMMA constassign)* SEMICOLON;
constassign: i:IDENT EQUALS n:NUMBER { checkRange(n); defineConst(i, n); };
vardecl: "VAR" i1:IDENT {defineVar(i1);} (COMMA i2:IDENT {defineVar(i2);})* SEMICOLON;
procdecl: "PROCEDURE"^ i:IDENT {defineProcedure(i);} SEMICOLON! block SEMICOLON! {popScope();};
statement: (i:IDENT {checkForVariable(i);} ASSIGNOP^ expression
| "CALL"^ i2:IDENT {checkForProcedure(i2);}
| QUESTION^ i3:IDENT {checkForVariable(i3);}
| EXCLAM^ i4:IDENT {checkForValue(i4);}
| "BEGIN"^ statement (SEMICOLON! statement)* "END"!
| "IF"^ condition "THEN"! statement
| "WHILE"^ condition "DO"! statement)?;
condition: "ODD"^ expression
| expression (EQUALS^ | DIAMOND^ | LT^ | LEQ^ | GT^ | GEQ^) expression;
expression: (PLUS^ | MINUS^)? term ((PLUS^ | MINUS^) term)*;
term: factor ((TIMES^ | OVER^) factor)*;
factor: i:IDENT {checkForValue(i);}
| n:NUMBER {checkRange(n);}
| LPAREN! expression RPAREN!;
|
Beispielinhalt der Symboltabelle
Für das in Abschnitt "Erzeugen des Syntaxbaumes" eingeführte Beispiel enthält die Symboltabelle nach dem Parsen folgende Informationen:

Abbildung 3.2: Sichtbare Definitionen des Hauptprogrammes

Abbildung 3.3: Sichtbare Definitionen der Prozedur init_y
Numerieren der Prozeduren
Im übersetzten Programm wird der Code als eine Folge von Anweisungen im Hauptspeicher repräsentiert, eine hierarchische Schachtelung der Prozeduren ist dann nicht mehr möglich. Stattdessen gibt es nur noch Sprünge zu einem bestimmten Speicherbereich. Dazu ist es notwendig, dass alle Prozeduren eindeutig benannt sind, was im Quellcode nicht gegeben ist, da dort mehrere Prozeduren den gleichen Namen haben können, wenn sie in verschiedenen Gültigkeitsbereichen definiert sind.
Für jede gefundene Prozedur wird eine eindeutige Nummer vergeben und in ihrer ProcedureDef gespeichert. (In der eigentlichen Implementierung wird fälschlicherweise diese Nummer in ScopeDef gespeichert, statt in ProcedureDef. Da in PL0 aber ein Gültigkeitsbereich immer identisch mit einer Prozedur ist, verursacht das keine Fehler). Die Vergabe der Nummer entspricht der Reihenfolge der Prozedurendeklarationen im Quellcode. Folgendes Beispiel soll dies veranschaulichen. Man beachte, dass auch das Hauptprogramm eine ProcedureDef ist.
VAR a; //Hauptprogramm beginnt: scopeNumber = 0
PROCEDURE proca; //Prozedur proca beginnt: scopeNumber = 1
PROCEDURE procaa; //Prozedur procaa beginnt: scopeNumber = 2
VAR c;
BEGIN
!c;
END;
BEGIN
a := 10;
END;
PROCEDURE procb; //Prozedur procb beginnt: scopeNumber = 3
VAR c;
BEGIN
!a;
END;
BEGIN
a:=5;
END.
|
Diese scopeNumbers werden später für die bereits erwähnte Konvertierung von Prozeduraufrufen in Sprünge verwendet.
Anmerkung: Obiger Beispielcode ist so nicht kompilierbar, da der Parser die Kommentare nicht erkennt. Vor dem Übersetzen sind die Kommentare manuell zu entfernen.
 Scanner und Parser Scanner und Parser | Übersetzung in Zwischencode  |