Optimierungsmöglichkeiten allgemein
Linearisierter Zwischencode bietet eine sehr gute Möglichkeit, maschinenunabhängige Optimierungen durchzuführen, da er noch völlig architekturungebunden ist. In der Literatur werden dazu verschiedenste Verfahren diskutiert, welche als gute Referenz dienen und in den meisten Compilern genutzt werden. Gängige Verfahren auf dem Gebiet der Optimierung sind beispielsweise Vektorisierung von Schleifen, Deth-Code-Elimination, Constant-Propagation und optimierte Basic-Block-Anordnung. Mit Blick auf eine bestimmte Zielarchitektur bietet sich eine weitere Möglichkeit, indem äquivalente Prozessoroperationen durch die jeweils günstigere, wobei sich günstiger auf den Zeitkonsum bezieht, ausgetauscht werden.
Death-Code-Elimination
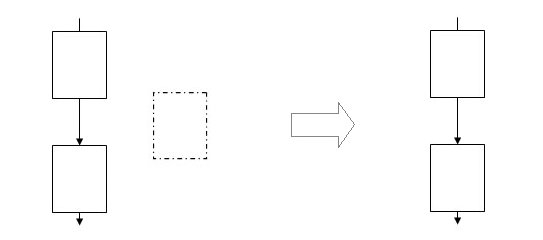
Abbildung 6.1: links mit totem Basic-Block, rechts ohne
Constant-Propagation
Bei dem Verfahren des Constant-Propagation werden alle Ausdrücke, deren Wert bei der Compilierung ermittelt werden kann, errechnet und an Stelle der Ausdrücke gesetzt, wodurch sich eine Reduktion von Prozessoroperationen ergibt. Desweiteren werden alle Vorkommen einer bereits initialisierten Variablen durch ihren konkreten Wert im Zwischencode ersetzt, solange sich ihr Wert nicht verändert. Sie werden durch Analyse der Programmstruktur ermittelt. Somit können Speicherzugriffe vermieden werden, da ein solcher Immediate-Wert oftmals direkt ein ein Befehlswort des Prozessores hineincodiert werden kann. Außerdem erspart man sich mitunter die Verfolgung mehrerer statischer Links.
Optimierte Basic-Block Anordnung
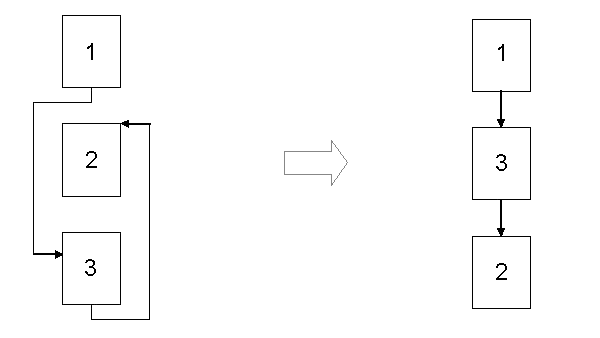
Abbildung 6.2: Optimierung der Basic-Block-Reihenfolge
Kostenoptimierung von Operationen
Bei der Kostenoptimierung von Operationen wird die für die einzelnen Prozessoroperationen verbrauchte Zeit als Maß herangezogen. Je schneller eine Prozessoroperation ausgeführt werden kann, d.h. je weniger Taktzyklen sie verbraucht, desto günstiger wird sie bewertet. Mit diesem Maß ist es nun möglich, vorgefundene Operationen auf eventuell vorhandene äquivalente Operationen zu überprüfen. Werden welche gefunden, so kann von ihnen diejenige ausgewählt werden, welche am günstigsten ist. So ist z.B. ein Shift äquivalent zur Multiplikation oder Division mit Vielfachen von 2. Das Shift wird allerdings günstiger ausgeführt, weshalb mögliche Vorkommen von Multiplikationen und Divisionen mit Vielfachen von 2 durch entsprechende Shifts ersetzt werden können.
binop(*, 1,4) ==> binop(<<, 1, 2) |
Es gibt weitere Möglichkeiten der Kostenoptimierung, diese sind allerdings hochgradig maschinenabhängig, so dass sie nicht auf dem Zwischencode durchgeführt werden können und hier nicht weiter betrachtet werden.
Implementierte Optimierungen
Im Rahmen des Hauptseminares ist es zeitlich nicht möglich, alle bereits erwähnten Optimierungen zu nutzen, der Aufwand ist nicht zu unterschätzen. Deshalb wurden exemplarisch zwei herausgegriffen. Dabei handelt es sich um ein vereinfachtes Constant-Propagation und um die Kostenoptimierung von Operationen, speziell den bereits erwähnten Multiplikationen. Siehe dazu nachfolgende Zwischencodebeispiele.
Ein simples Beispiel für Constant-Propagation, welches sich darauf beschränkt, arithmetische Ausdrücke mit Konstanten zusammenzufassen.
TEMP(Temp 2) = +(TEMP(Temp fp), CONST(12))
TEMP(Temp 3) = +(CONST(3), CONST(4))
TEMP(Temp 4) = +(TEMP(Temp 3), CONST(5))
TEMP(Temp 5) = +(TEMP(Temp 4), CONST(6))
MOVE(MEM(TEMP(Temp 2)), TEMP(Temp 5))
|
Und die optimierte Version:
TEMP(Temp 2) = +(TEMP(Temp fp), CONST(12))
MOVE(MEM(TEMP(Temp 2)), CONST(18))
|
Nachfolgend ist eine Demonstration aufgelistet, wie eine Multiplikation mit Vielfachen von 2 durch eine entsprechende Shift-Operation ersetzt wird.
TEMP(Temp 10) = *(MEM(TEMP(Temp 9)), CONST(4)) |
Und die optimierte Version:
TEMP(Temp 10) = LSHIFT(MEM(TEMP(Temp 9)), CONST(2))
|
 Linearisierung des Zwischencodes Linearisierung des Zwischencodes | Das Linux-Backend  |