Der Parsergenerator ANTLR
Der Generator, der für die Erzeugung des Parsers und des Scanners zur Anwendung kommen sollte, ist der ANTLR Parser Generator. Die erzeugten Scanner und Parser sind in Java geschrieben. Eine Besonderheit ist, dass sowohl Scanner als auch Parser rekursiv absteigend arbeiten.
Definition des Scanners
Die Definition des Scanners ist ziemlich geradlinig. Er wird im Wesentlichen aus folgenden Anweisungen erzeugt:
class PL0Lexer extends Lexer;
options {
k = 2; //2 symbols lookahead because with k=1
//there is an ambiguity < / <= and > / >=
}
WS: ( ' '
| '\t'
| '\f'
// handle newlines
| ( "\r\n" // DOS
| '\r' // Mac
| '\n' // Unix
) { newline(); } //if a new line is found,
//increase internal line number
//(for error messages)
) { $setType(Token.SKIP); }; //all tokens which are matched
//as whitespace should be skipped
DOT: '.';
COMMA: ',';
SEMICOLON: ';';
ASSIGNOP: ":=";
QUESTION: '?';
EXCLAM: '!';
LT: '<';
LEQ: "<=";
GT: '>';
GEQ: ">=";
DIAMOND: '#';
EQUALS: '=';
PLUS: '+';
MINUS: '-';
TIMES: '*';
OVER: '/';
LPAREN: '(';
RPAREN: ')';
NUMBER: ('0'..'9')+;
IDENT: ('a'..'z'|'A'..'Z'|'_') ('a'..'z'|'A'..'Z'|'_'|'0'..'9')*;
|
Auf die Definition der Schlüsselwörter wurde verzichtet, denn aufgrund des rekursiv absteigenden Arbeitens des Scanners kam es zu Mehrdeutigkeiten, es wurde nicht erkannt, ob ein Schlüsselwort oder ein Bezeichner auftritt. Laut Dokumentation sollte es zwar möglich sein, Schlüsselworte als solche zu markieren, damit sie Priorität vor normalen Bezeichnern haben, aber in der verwendeten Version 2.7.3 funktionierte das nicht, auch war die Dokumentation zu dem Thema in sich widersprüchlich. Deshalb wurde das Erkennen von Schlüsselworten in den Parser verschoben. In welcher Form das geschah, wird im Abschnitt Definition des Parsers erklärt.
Definition des Parsers
Die Definition des Parsers erfolgte in mehreren Schritten. Zuerst wurde die PL/0-EBNF-Definition 1:1 übertragen:
class PL0Parser extends Parser;
program: block DOT;
block: (constdecl)? (vardecl)? (procdecl)* statement;
constdecl: "CONST" constassign (COMMA constassign)* SEMICOLON;
constassign: IDENT EQUALS NUMBER;
vardecl: "VAR" IDENT (COMMA IDENT)* SEMICOLON;
procdecl: "PROCEDURE" IDENT SEMICOLON block SEMICOLON;
statement: (IDENT ASSIGNOP expression
| "CALL" IDENT
| QUESTION IDENT
| EXCLAM IDENT
| "BEGIN" statement (SEMICOLON statement)* "END"
| "IF" condition "THEN" statement
| "WHILE" condition "DO" statement)?;
condition: "ODD" expression
| expression (EQUALS | DIAMOND | LT | LEQ | GT | GEQ) expression;
expression: (PLUS | MINUS)? term ((PLUS | MINUS) term)*;
term: factor ((TIMES | OVER) factor)*;
factor: IDENT
| NUMBER
| LPAREN expression RPAREN;
|
Die Schlüsselwörter wurden hier direkt als Zeichenketten definiert (z.B. "WHILE"), nicht als Morphem, wie das üblich ist. Der Grund ist das in Abschnitt Definition des Scanners erwähnte Problem der Doppeldeutigkeit von Bezeichnern und Schlüsselwörtern.
Erzeugen des Syntaxbaumes
Der degenerierte Syntaxbaum
Mit dem aus obiger Definition erzeugten Parser war es möglich, syntaktisch korrekte PL/0 Programme zu parsen und bei Fehlern benachrichtigt zu werden. Da aber ein Übersetzer gebaut werden sollte, wird ein Syntaxbaum benötigt. Dieser lässt sich mit semantischen Aktionen aufbauen, aber ANTLR unterstützt die Erzeugung von Syntaxbäumen schon von Haus aus.
Zuerst ist das Flag buildAST = true zu setzen. AST steht für Abstract Syntax Tree. Der resultierende Syntaxbaum ist allerdings linear, ohne jede Struktur (ein sogenannter degenerierter Syntaxbaum) und für eine Übersetzung nicht zu verwenden. Hier ein Beispiel:
CONST a = 3, b = 4;
VAR x, y, z;
PROCEDURE init_y;
VAR input;
BEGIN
?input;
y := -2 * input;
END;
BEGIN
?x;
CALL init_y;
z := a * y - 19 / b;
IF x < 30 THEN
BEGIN
!z;
END
END.
|
Dies würde "übersetzt" zu CONST a = 3 , b = 4 ; VAR x , y , z ; PROCEDURE init_y ; VAR input ; BEGIN ? input ; y := - 2 * input ; END ; BEGIN ? x ; CALL init_y ; z := a * y - 19 / b ; IF x < 30 THEN BEGIN ! z ; END END .
Erzeugung eines richtigen Syntaxbaumes
Der Aufbau des Syntaxbaumes lässt sich folgendermaßen steuern:
- Ein mit
^ausgezeichnetes Morphem wird zur Wurzel eines (Teil)Syntaxbaumes. - Ein mit
!ausgezeichnetes Morphem wird nicht mit in den Syntaxbaum aufgenommen. Dies ist bei Morphemen nützlich, die keine semantische Bedeutung haben, zum Beispiel bei einem Semikolon.
Die nächste Stufe war folgende Parserdefinition:
class PL0Parser extends Parser; options { buildAST = true; } tokens { PROGRAM; } program: block DOT! {#program = #([PROGRAM, "PROGRAM"], program);}; block: (constdecl!)? (vardecl!)? (procdecl)* statement; constdecl: "CONST" constassign (COMMA constassign)* SEMICOLON; constassign: IDENT EQUALS NUMBER; vardecl: "VAR" IDENT (COMMA IDENT)* SEMICOLON; procdecl: "PROCEDURE"^ IDENT SEMICOLON! block SEMICOLON!; statement: (IDENT ASSIGNOP^ expression | "CALL"^ IDENT | QUESTION^ IDENT | EXCLAM^ IDENT | "BEGIN"^ statement (SEMICOLON! statement)* "END"! | "IF"^ condition "THEN"! statement | "WHILE"^ condition "DO"! statement)?; condition: "ODD"^ expression | expression (EQUALS^ | DIAMOND^ | LT^ | LEQ^ | GT^ | GEQ^) expression; expression: (PLUS^ | MINUS^)? term ((PLUS^ | MINUS^) term)*; term: factor ((TIMES^ | OVER^) factor)*; factor: IDENT | NUMBER | LPAREN! expression RPAREN!; |
Der resultierende Parser liefert bei Anwendung auf das Beispielprogramm folgenden Syntaxbaum:
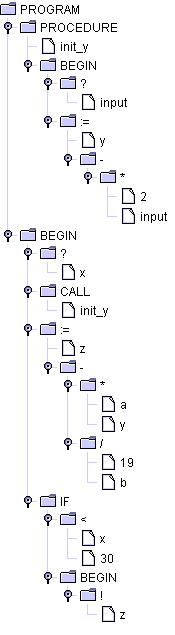
Abbildung 2.1: Syntaxbaum
Es ist zu erkennen, dass die Konstanten- und Variablendeklaration nicht mit in den Syntaxbaum aufgenommen wurden. Das ist auch nicht notwendig, da sie nicht direkt zur Codeerzeugung benötigt werden. Sie sind allerdings in die Symboltabelle einzutragen, wie das geschieht, wird im Kapitel Die Symboltabelle beschrieben.
Besondere Erwähnung verdient die Anweisung {#program = #([PROGRAM, "PROGRAM"], program);}. Alles, was nach syntaktischen Regeln in geschweiften Klammern steht, ist eine semantische Aktion, die bei Anwendung der Regel ausgeührt wird. Bevor erläutert wird, was die semantische Aktion #program = #([PROGRAM, "PROGRAM"], program); bewirkt, sei die Syntax näher erklärt (entnommen aus dem ANTLR Manual).
Ein Baum wird in ANTLR in linearisierter Form dargestellt. Beispielsweise steht #(A B C) für einen Baum, der A als Wurzel hat und B und C als Kinder. Bäume lassen sich beliebig schachteln, so wäre ein Baum mit der Wurzel A und den Kindern B und C, wobei C selbst die Kinder D und E hat, zu notieren als #(A B #(C D E)).
Die obige Regel besagt nun: "Ersetze den standardmäßig von program generierten Knoten durch den Baum #(PROGRAM, program)". Es wird also die Wurzel PROGRAM eingefügt. Dabei bedeutet [PROGRAM, "PROGRAM"], dass der neue Knoten intern PROGRAM heißen und seine Bezeichnung (z.B. für Ausgaben) auch PROGRAM sein soll.
Der Grund für das explizite Eingreifen in die Baumkonstruktion ist, dass sonst der Baum nicht vollständig gespeichert würde. Die erste Wurzel, die bei der Übersetzung gefunden wird, wäre die Wurzel des gesamten Syntaxbaumes, alle Teilbäume, die auf der selben Hierarchiestufe stehen, gingen verloren. Für das obige Beispiel hieße das, der Syntaxbaum bestünde nur aus der ersten definierten Unterprozedur:
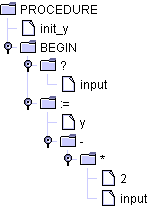
Abbildung 2.2: Abgeschnittener Syntaxbaum
Die Anweisung sorgt also dafür, dass alle Teilbäume der obersten Ebene (Unterprozeduren und Hauptprogramm) unter einer gemeinsamen Wurzel stehen. Der Wurzelknoten PROGRAM muss definiert sein, das geschieht in der tokens-Sektion.
Damit war die Definition des Parsers vorerst abgeschlossen. Allerdings wurde im Laufe der Compilerentwicklung zusätzliche Funktionalität benötigt, was weitere Veränderungen an der Parserdefinition erforderte. Auf diese Erweiterungen wird an passender Stelle im Detail eingegangen.
 Einführung Einführung | Die Symboltabelle  |